老婆最近生气了,说强哥不肯给她买iPhone X。强哥觉得挺委屈的,强哥是小气的人么。老婆要买iPhone X,强哥当然支持了。强哥立刻转了一笔巨款给老婆
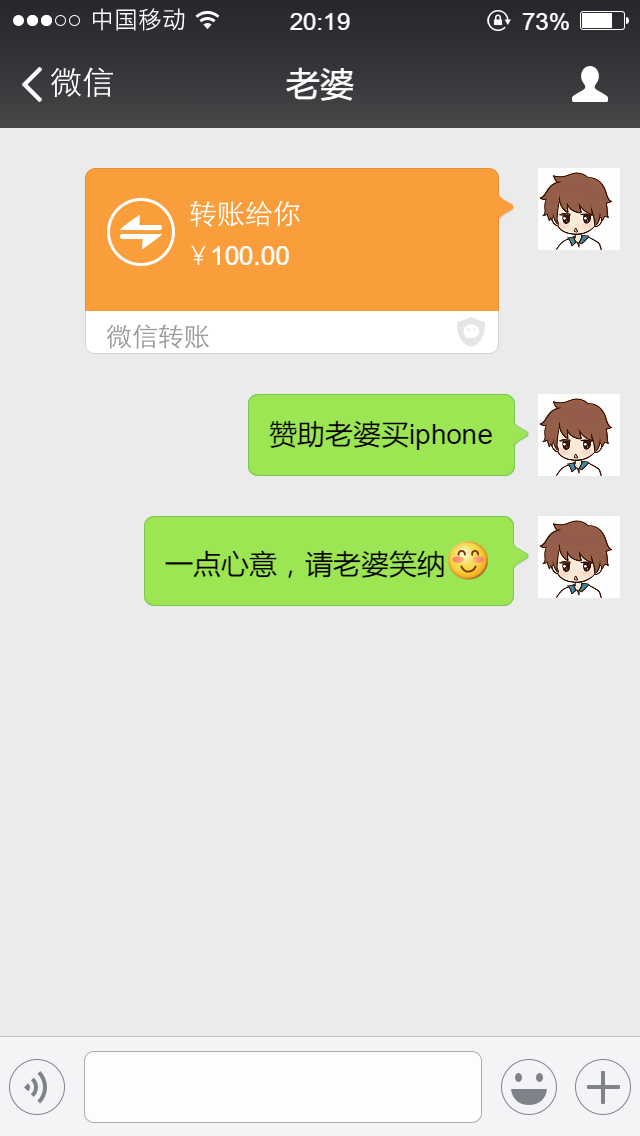
发完转账,老婆就把强哥给拉黑了。强哥当时的心情是这样的

强哥挺郁闷的,强哥到底做错了什么,老婆要这样对我。
带着沉重的心情,强哥决定深入了解一下老婆为什么这么喜欢iPhone X,于是强哥用Python爬取淘宝店铺的数据分析了一下iPhone X到底有多热卖。
我们先来看下淘宝上的销量数据长什么样。
淘宝上的销量数据有两种方式估算,一种方式是用累计付款人数近似销量,像下面这种

显示在这个数字里的每个人都至少购买了一部手机,所以总销量一定大于等于累计付款人数。
淘宝上并不是每一家店铺都显示累计付款人数,对于下面这种只显示评论数的情况

就只能用评论数来估算销量了。具体怎么估算后面会提到。
知道怎么获得销量数据,接下类我们就开始爬数据了。
我们要爬的数据藏在下面高亮的URL里
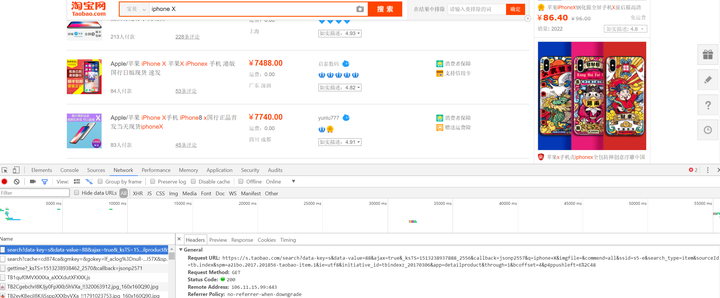
我们用Python的Scrapy框架来实现一个爬虫,爬取不同搜索页的URL
爬虫代码如下:
import time
import json
import re
import scrapy
import pymongo
def load_param():
try:
with open("/tmp/param") as f:
content = f.read()
data = json.loads(content)
start = data.setdefault("start", 0)
return start
except:
return 0
def save_param(start):
with open("/tmp/param", "wb") as f:
result = json.dumps({
"start": start,
})
f.write(result)
class QuotesSpider(scrapy.Spider):
name = "iphonex"
url_patt = 'https://s.taobao.com/search?data-key=s&data-value=%d&ajax=true&_ksTS=1513178695257_1962&callback=jsonp1963&q=iphone+x&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306&app=detailproduct&through=1&bcoffset=4&p4ppushleft=6%%2C48'
def start_requests(self):
start = load_param()
url = self.url_patt % (start)
self.start = start
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
content = response.body
patt = r'jsonp\d+\((.*)\);'
matched = re.search(patt, content, re.MULTILINE)
data = json.loads(matched.group(1))
items = data["mods"]["itemlist"]["data"]["auctions"]
client = pymongo.MongoClient()
db = client["iphonex"]
new_items = db.items.insert_many(items)
self.start = self.start + 44
save_param(self.start)
url = self.url_patt % (self.start)
time.sleep(2)
yield scrapy.Request(url=url, callback=self.parse)
我们爬得温柔点,这里设了爬完一次休息2秒再爬。
爬完的数据存入了mongodb,接下来我们将数据从mongodb中读出来,去除不相关的产品和重复的产品,估算一下缺失累计付款人数商品的销量数据,然后统计总的销量和销售额。
这里重点讲述一下怎么用评论数来估算商品销量。
淘宝上的商品的评论只有在购买成功后才能添加,一次购买行为最多对应一条评论(首评,追评都会归结到一条)。按常理分析,商品累计付款人数和评论数应该呈正相关的关系。
我们提取mongodb里累计付款人数大于0并且评论数大于200的商品。销量太少的商品的评论数量可能会存在一定随机性,因此我们限定用于分析的商品的评论数必须大于200。
用散点图画出累计付款人数和评论数的关系,如下
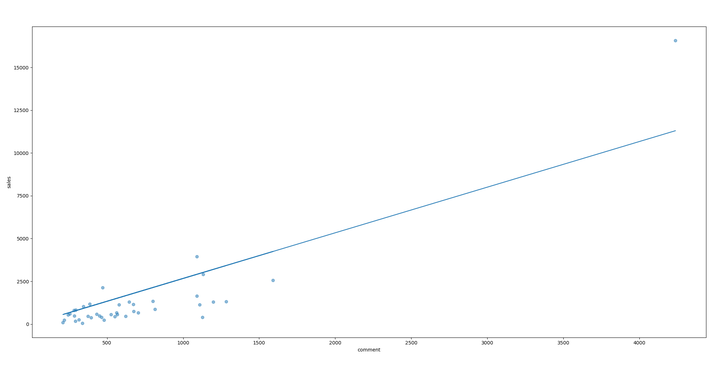
上图横轴是评论数,纵轴是累计付款人数,累计付款人数和评论数还是呈现很明显的正相关关系的。我们用线性来拟合这个关系,对于那些只有评论数的商品,我们用拟合出来的公式来推算该商品的累计付款人数,由此来估算销量。
数据分析部分的代码如下:
def get_iphonex():
client = pymongo.MongoClient()
db = client["iphonex"]
items = db["items"]
prices = []
sales = []
com_counts = []
urls = []
titles = []
nids = []
for item in items.find():
title = item["raw_title"]
if (re.search(r"iphonex", title, re.I) or \
re.search(r"iphone x", title, re.I)) and \
not re.search(r"iphone 8", title, re.I) and \
not re.search(r"iphone8", title, re.I):
titles.append(title)
else:
continue
nids.append(item["nid"])
url = item["detail_url"]
urls.append(url)
view_price = item.setdefault("view_price", "0")
prices.append(float(view_price))
comment_count = 0
if "comment_count" in item and item["comment_count"]:
comment_count = int(item["comment_count"])
com_counts.append(comment_count)
view_sales = item.setdefault("view_sales", "0")
matched = re.match(r'(\d+)', view_sales)
if matched:
view_sales_num = matched.group(1)
sales.append(int(view_sales_num))
else:
sales.append(-1)
pd.set_option('display.max_colwidth', -1)
df = pd.DataFrame({"price": prices, "sales": sales, "urls": urls, "titles": titles, "nids": nids, "comment_count": com_counts})
df.drop_duplicates(subset="nids", keep="last", inplace=True)
df_test = df[df.price>6000][(df.sales!=0) | (df.comment_count!=0)]
df_train = df_test[df_test.comment_count > 200][df_test.sales > 0]
reg = sklearn.linear_model.LinearRegression(fit_intercept=False)
reg.fit(df_train[["comment_count"]], df_train["sales"])
df_tofill = df_test[df_test.sales==0]
df_tofill["sales"] = reg.predict(df_tofill[["comment_count"]])
df_test[df_test.sales == 0] = df_tofill
print "iPhone X sold number:", df_test.sales.sum()
print "iPhone X sold money:", np.sum(df_test.sales*df_test.price)
get_iphonex()
上面这段代码有如下的输出:
iPhone X sold number: 194037.766983
iPhone X sold money: 1605100188.36
可以看到,至今为止,iPhone X在淘宝上共卖出了19万部,销售额达到了16亿多。
这个销售量到底什么水平呢?我们可以统计一下差不多同期上市的几款手机的销量,做个比较。
用同样的方法,我们从淘宝上爬取了iPhone 8,华为Mate 10,小米Mix 2的销量数据,将它们和iPhone X放在一起做比较,有如下的数据
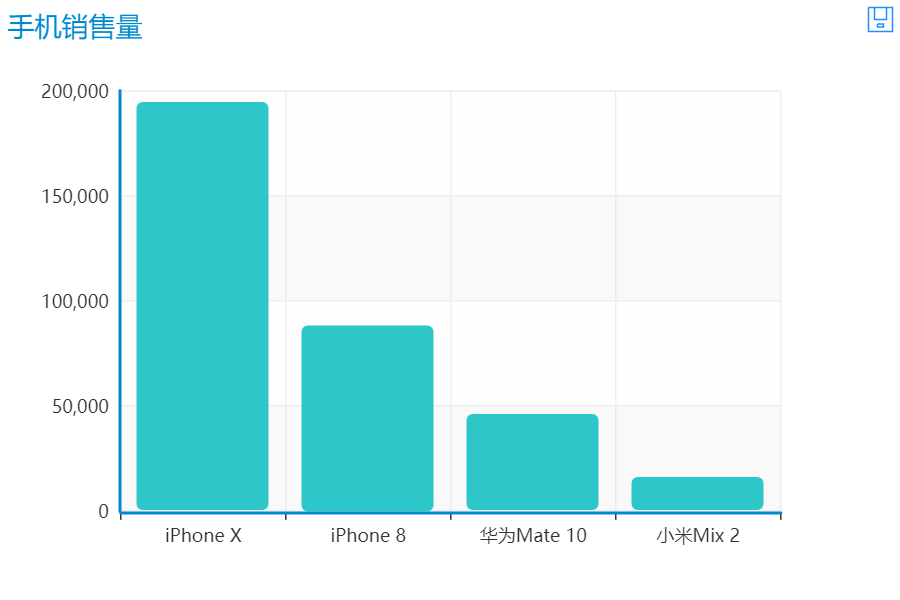
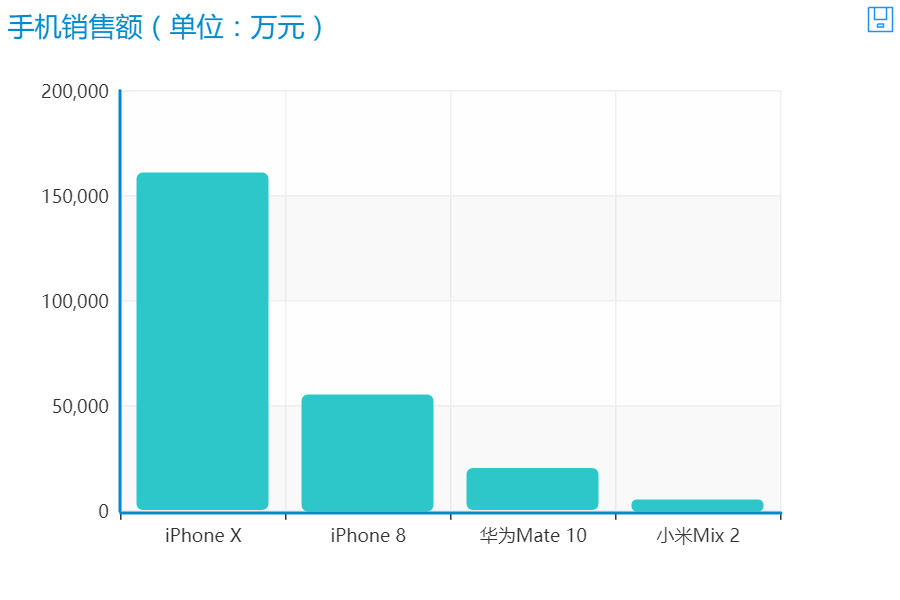
可以看到iPhone X无论在销量还是销售额上都遥遥领先,远远超过其他手机。
当然淘宝只是iPhone X的一个销售平台,同样在销售iPhone X的还有京东,苏宁,苹果线上和线下的实体商店等。由于很多大平台并不公开销量数据,要统计iPhone X总的销售量还有很大的难度。但根据之前新闻报道iPhone X开卖2小时招行销售额破20亿、双十一京东购机预约数量破200万、苹果商店门前排起长队、黄牛将一部手机价格炒到2万等这些来判断,这次的iPhone X一定是大受好评的。
至此,强哥算是明白老婆为什么这么喜欢iPhone X了。强哥知道错了,强哥这就给老婆买iPhone X去。